Project for Fastcode (officially Advanced Systems Lab, DPHPC) at ETH, spring 2025.
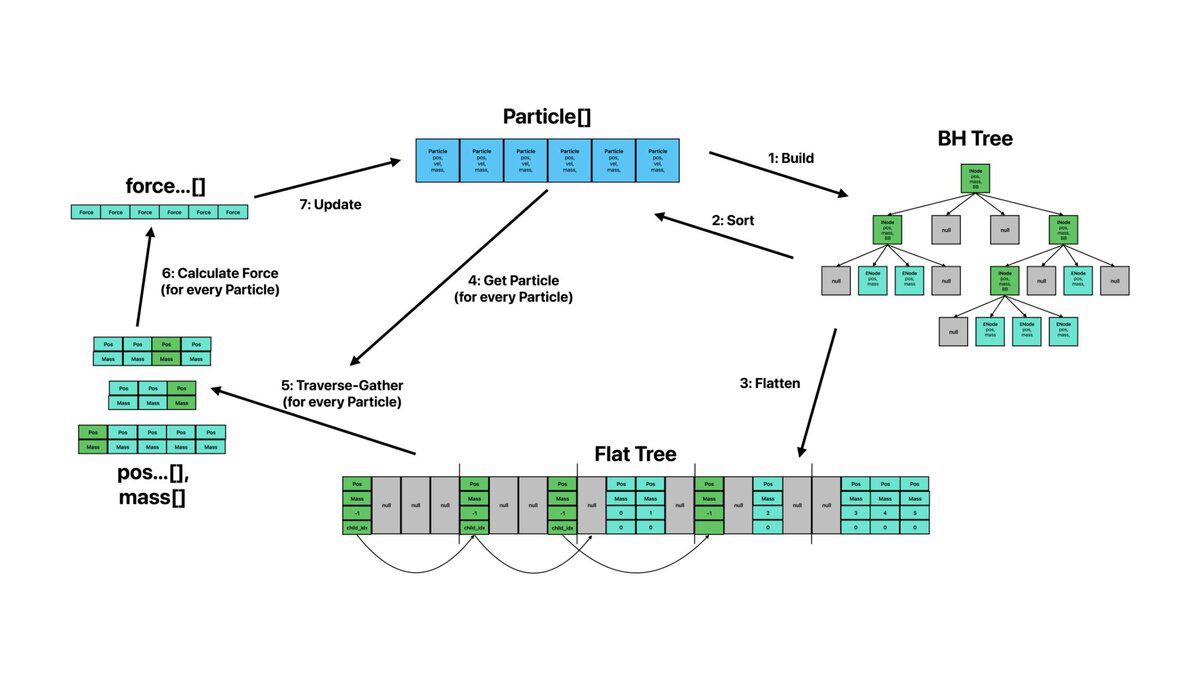
The Barnes-Hut algorithm approximates N-body forces in O(n log n) by grouping distant particles in an octree. Most “fast” Barnes-Hut codes scale horizontally - threads, GPU, MPI - and leave the per-core kernel as the textbook recursive walk. We went the other way: keep it single-threaded and squeeze the core. Killed the trigonometric calls (more than half the runtime) by replacing them with algebraic identities. Replaced the pointer-chasing octree with a struct-of-arrays FlatTree. Switched recursive DFS to an iterative stack. Sorted particles along a Hilbert-ish curve for cache locality. Hand-unrolled the traversal stack via layered C macros to expose ILP across the cyclic stack-pop dependency (~45,000 lines of expanded C in the final version). Then ported the whole thing to NEON for ARM and AVX-512 for Skylake. End result: 32× speedup over the textbook baseline and roughly 58 % of the instruction-mix roofline.
Brutal in an already packed semester, but immensely fun. The kind of project where you sit with perf for hours and slowly start to understand what your CPU is actually doing. I was on EPFL exchange that semester, so I did the whole course remotely and only travelled back to Zürich for the midterm and final presentation.


